AI + Enterprise Architecture
Your data strategy is your AI strategy: the database as context engine
The API era of AI is over. Enterprise-grade agents need databases that serve as context engines—with vector pipelines, row-level security, and architecture-first thinking.
Most enterprise AI projects stall not because the model underperforms, but because the architecture around it was never designed for production. Google Cloud’s new “Data Strategy = AI Strategy” series names what many CTOs already feel: 2026 is the year developers must become AI architects.
The core thesis is simple and important: if your data is messy, your agent will be confidently wrong. The API-wrapper era (2024–2025) is giving way to full-stack AI architecture where the database isn’t just storage—it’s the context engine.
The shift: from prompt engineering to architecture engineering
In the API era, shipping an AI feature meant calling an LLM endpoint and wrapping a UI around it. That worked for demos. It fails at enterprise scale because it ignores three pillars:
- Speed — round-trip latency between app, embedding service, vector DB, and LLM compounds fast
- Scale — processing millions of embeddings through application-layer loops is a bottleneck by design
- Security — LLMs have no concept of data authorisation; that must live in the data layer
The architectural answer is to push intelligence down into the database. Google Cloud’s approach uses PostgreSQL-compatible services (AlloyDB, Cloud SQL) as both the relational store and the vector engine, eliminating a class of infrastructure that previously sat between the app and the data.
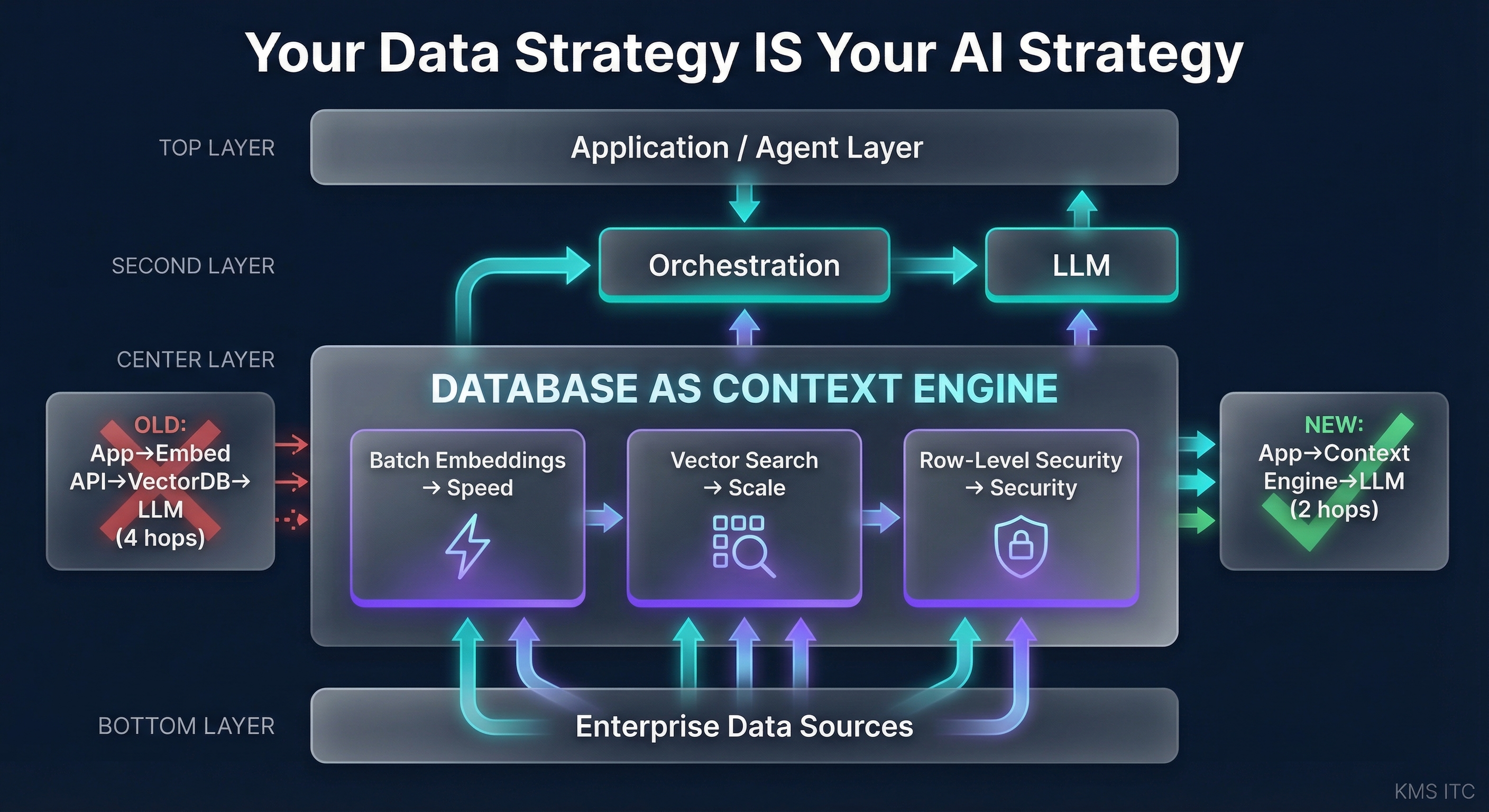
The database as context engine: why it matters
Traditional RAG pipelines follow this path: app → embedding API → vector DB → LLM → app. Every hop adds latency, failure modes, and security surface.
When the database itself generates embeddings, stores vectors, and enforces access control, the architecture simplifies:
- Batch embedding at the data layer: AlloyDB can generate embeddings at scale directly within the database—no application-layer loops. One million vectors, zero loops.
- Row-level security (RLS) for AI agents: Instead of trusting your agent to respect data boundaries, RLS enforces them at the query level. Agent A sees only Agent A’s data. This is non-negotiable in regulated industries and increasingly expected everywhere.
- Serverless deployment with managed identity: Cloud Run + AlloyDB with managed connection strings means the application layer stays thin and secure.
This is the “private vault” architecture: zero-trust intelligence where data governance is baked into the database, not bolted onto the agent.
The enterprise architecture implication
This isn’t just a Google Cloud pattern. The broader principle applies across every cloud:
| Principle | What it replaces |
|---|---|
| Database-native embeddings | External embedding service + vector DB sidecar |
| Row-level security for agents | Application-layer access control (fragile) |
| Managed identity + serverless | Long-lived credentials + always-on compute |
| Architecture-first design | Prompt-first prototyping |
The real shift is organisational. Teams that treat AI as “just another API” will keep building fragile prototypes. Teams that invest in AI architecture as a platform capability—with explicit data contracts, security boundaries, and scalability patterns—will ship production systems.
What to do next
- Audit your current AI data flow. Map every hop between user request and LLM response. Each hop is latency, cost, and risk.
- Evaluate database-native vector support. Whether it’s AlloyDB, pgvector on Aurora, or Azure Cosmos DB, the trend is clear: push vector operations closer to the data.
- Implement row-level security for AI workloads. If your agents can see data they shouldn’t, that’s not an AI problem—it’s an architecture problem. Fix it in the data layer.
- Staff for AI architecture, not just AI development. The skillset gap in 2026 isn’t “can we call an LLM”—it’s “can we design a secure, scalable, cost-effective AI stack.”
- Run the hands-on labs. Google’s codelab series walks through each layer: provisioning, deployment, real-time inference, batch embeddings, and zero-trust agents.
Sources
- Data Strategy = AI Strategy — Google Cloud Blog
- AlloyDB Quick Setup Codelab
- One Million Vectors, Zero Loops — AlloyDB Codelab
- Zero Trust Agents with RLS — AlloyDB Codelab
Your AI is only as good as its data architecture. If you’re still treating the database as “just storage,” it’s time to rethink the stack.