Cloud Architecture
EC2 G7e (Blackwell) changes the shape of enterprise inference: fewer compromises, new failure modes
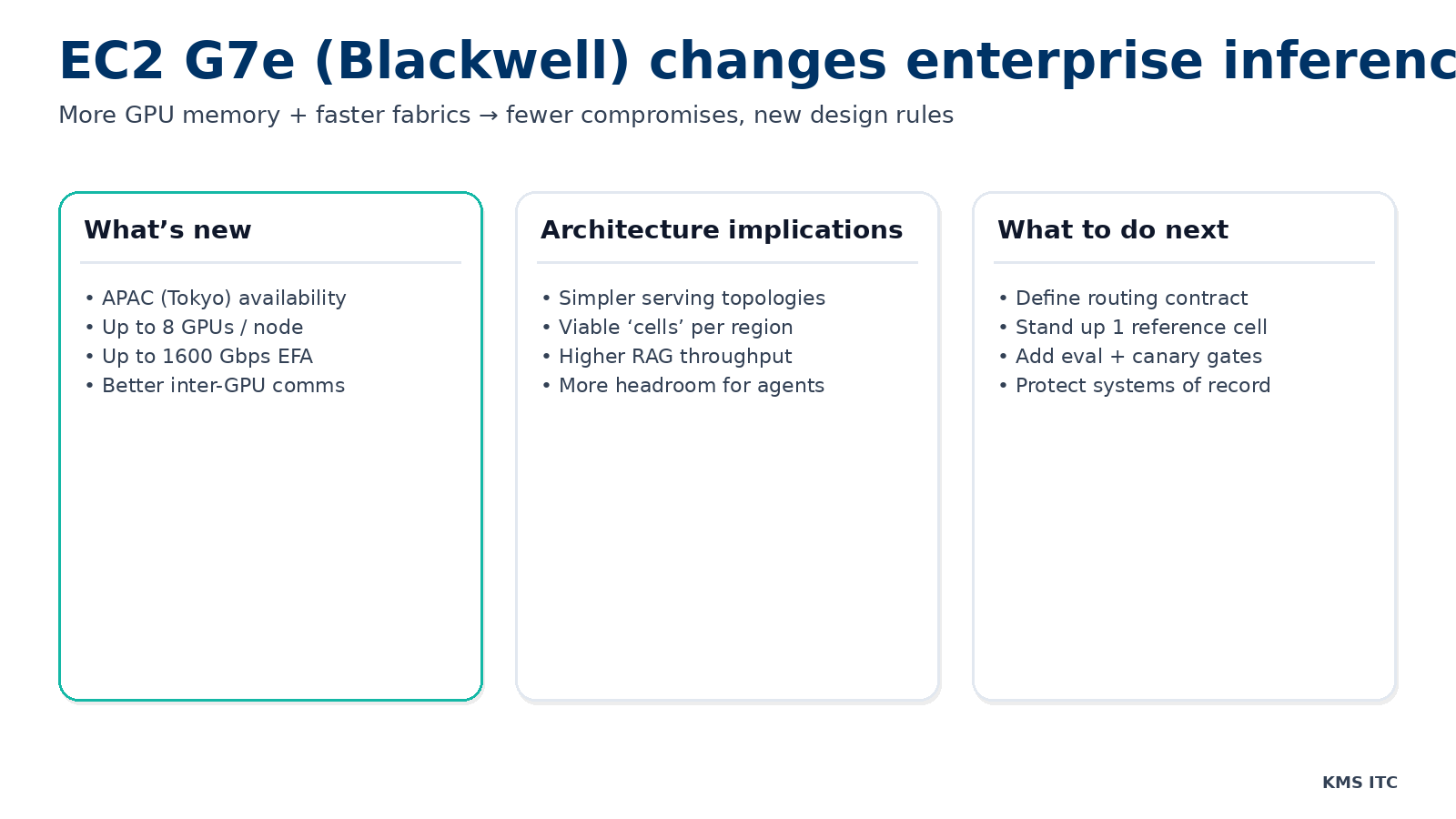
AWS’s G7e instances (NVIDIA RTX PRO 6000 Blackwell, up to 8 GPUs and 1600 Gbps EFA) are now in APAC (Tokyo). Here’s what that means for LLM serving, agent workloads, and platform architecture.
The bottleneck in enterprise GenAI rarely starts as “model quality”. It starts as latency, cost, and operability.
AWS has expanded Amazon EC2 G7e availability to Asia Pacific (Tokyo), bringing NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs with up to 8 GPUs per instance (768 GB total GPU memory) and up to 1600 Gbps networking with EFA.
That isn’t just “faster GPUs”. It changes what good looks like for LLM serving platforms: fewer sharded deployments, more headroom for agentic workloads, and a new set of design constraints around placement, networking, and release governance.
1) The capability jump (what matters, not the spec sheet)
From an architecture perspective, three G7e traits matter most:
-
More GPU memory per node (and per GPU)
- Larger models and larger KV caches fit without extreme sharding.
- More room for multi-tenant isolation strategies that don’t collapse under peak load.
-
Faster node-to-node communication (EFA + GPUDirect RDMA)
- Multi-node fine-tuning/training becomes viable for “small scale” platform teams.
- More importantly: model-parallel serving patterns become less painful (but still not free).
-
I/O and data-path improvements
- High-throughput pipelines for RAG, embeddings, and multi-modal inputs are less likely to bottleneck on CPU↔GPU or storage.
The enterprise takeaway: you can move more workloads from “GPU science project” to repeatable platform product.
2) What G7e enables for the platform operating model
Enterprises typically want both innovation and control:
- multiple internal teams shipping assistants/agents
- shared controls for security, cost, privacy, and reliability
G7e is a forcing function to treat “model serving” as a tier-0 platform capability (not a per-team pet cluster).
The minimal platform shape that scales has three layers:
- Front door — shared gateway with authentication and per-tenant quotas
- Routing layer — single abstraction for model selection, region, workload tier, and safety policy
- Capacity portfolio — on-demand for baseline interactive SLOs; spot for burst and batch; savings plans where utilisation is proven
The key platform moves
- Standardise the front door (gateway + auth + quotas) so teams don’t build bespoke access paths.
- Put routing behind a single abstraction:
- “which model?”
- “which region?”
- “which tier (interactive vs batch)?”
- “which safety policy?”
- Operate GPU capacity as a portfolio:
- on-demand for baseline
- spot for burst/batch
- savings plans where utilisation is proven
3) The tradeoffs (what bites you in production)
Tradeoff A: Bigger nodes reduce sharding… but increase blast radius
Consolidating on fewer, larger nodes improves throughput and simplifies deployment. But the unit of failure becomes larger:
- one node draining can remove a big fraction of capacity
- noisy-neighbour incidents become costlier
Mitigation: use cell-based design:
- 2–4 identical cells per region
- each cell has its own serving pool + cache + routing targets
- a single cell can be drained without a full-region brownout
Tradeoff B: EFA helps scale-out… but it’s not “just networking”
EFA changes the performance profile for inter-instance comms by bypassing parts of the kernel networking path (via Libfabric/NCCL for relevant workloads).
But it adds constraints:
- placement and topology start to matter more
- testing must include “real cluster shapes”, not just single-node benchmarks
Mitigation: bake topology into your platform product:
- golden instance families + sizes
- known-good driver/runtime combos
- capacity templates per workload class (interactive inference, batch inference, fine-tuning)
Tradeoff C: Faster inference increases the rate of mistakes
When latency drops, teams ship more agent steps per minute. That can increase:
- tool-call volume
- data access frequency
- downstream system load
Mitigation: make “agent guardrails” part of platform SLOs:
- tool allowlists + parameter schemas
- per-tenant budgets (cost, tool calls, tokens)
- circuit breakers to protect systems of record
4) What to do next (a 2-week action plan)
If you’re a CTO / enterprise architect / platform lead, here’s the practical sequence:
-
Classify workloads into 3 tiers:
- Tier 1: interactive assistants (tight latency SLO)
- Tier 2: agent workflows (bursty, tool-heavy)
- Tier 3: batch (offline summarisation, indexing, evals)
-
Build a routing contract (API + policy) that all apps use.
-
Stand up one reference cell on G7e:
- autoscaling policy
- load test harness
- failure drills (drain node, kill cache, degrade region)
-
Add release controls:
- pre-prod eval gates
- canary by tenant
- rollback that is routing-first (flip traffic), not “redeploy everything”.
5) Summary (what to remember)
- G7e isn’t a “faster GPU”. It’s an architecture unlock for enterprise inference platforms.
- The win is operational: fewer heroic sharding patterns, more predictable latency, and better multi-tenant headroom.
- The cost is governance: topology, routing, and safety controls become first-class.
Sources
- AWS What’s New: EC2 G7e in APAC (Tokyo)
- EC2 G7e instance family overview
- Elastic Fabric Adapter (EFA) on EC2
If you want a reference blueprint (cell design + routing contract + SLOs) for an enterprise LLM platform, reply with G7E BLUEPRINT and tell me your cloud (AWS/Azure/GCP) + primary workloads (assistants, agents, batch).