Enterprise Architecture
Fractional GPUs + Inference Gateway: a control-plane pattern for enterprise agentic AI
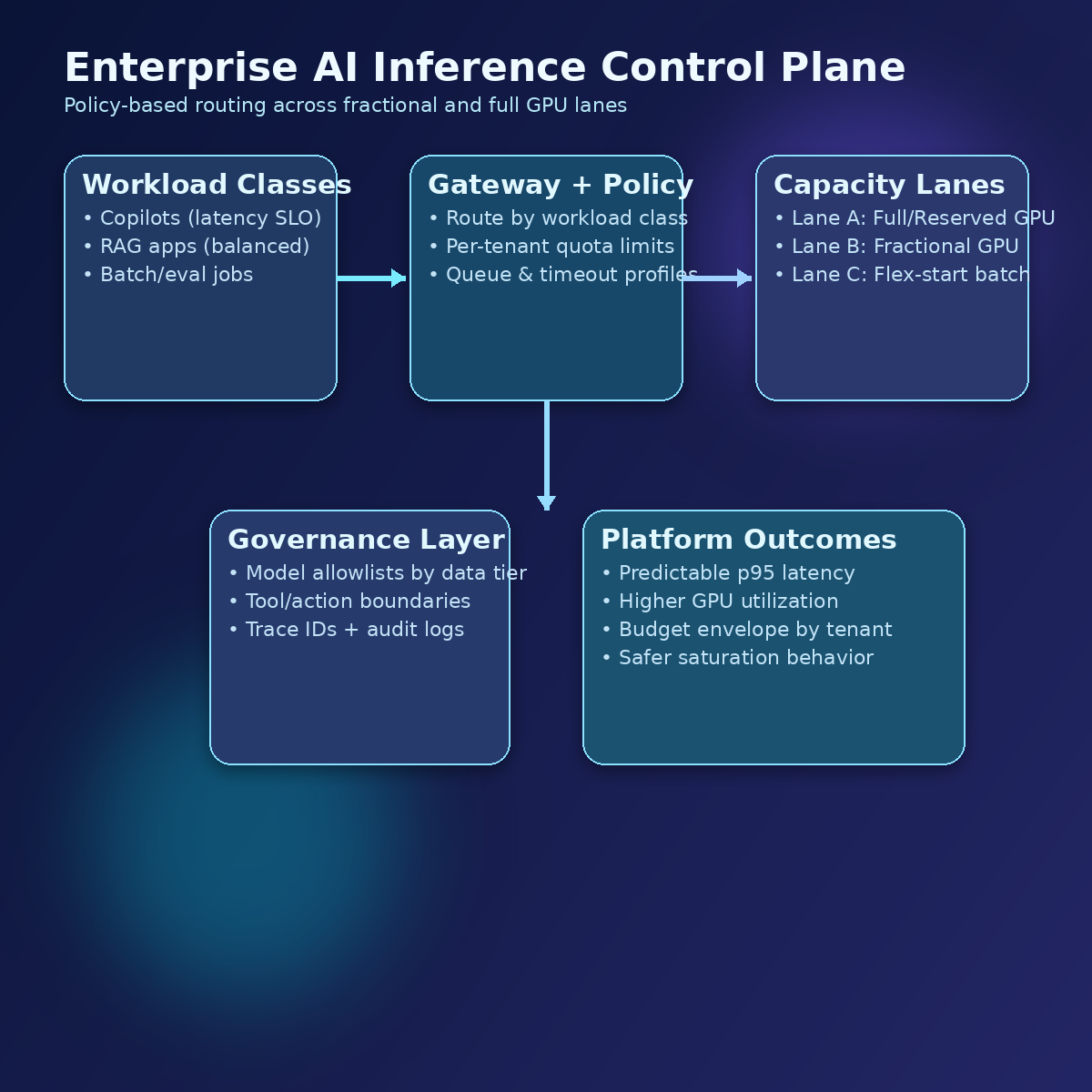
Google Cloud’s new fractional G4 VMs and Dynamo + GKE Inference Gateway integration point to a practical enterprise pattern: separate workload classes, route by policy, and treat GPU capacity as a governed control plane rather than an ad-hoc pool.
Most enterprise GenAI platforms still run like this: one shared GPU pool, best-effort scheduling, and incident-driven scaling.
That model breaks as soon as agentic workloads mix with traditional inference:
- interactive copilots need tight p95 latency,
- batch enrichment jobs need throughput,
- evaluation and red-team pipelines need cheap burst capacity.
Google Cloud’s latest stack direction—fractional G4 VMs plus NVIDIA Dynamo integrated with GKE Inference Gateway—is interesting because it enables a better operating model: capacity routing as architecture.
What changed (and why it matters)
Two shifts matter for CTOs and platform teams:
-
Fractional GPU shapes (1/2, 1/4, 1/8) on G4
- You can right-size inference and supporting workloads instead of overprovisioning full GPUs.
- This is not only a cost lever; it is a tenancy and workload-isolation lever.
-
Dynamo + GKE Inference Gateway integration
- The gateway becomes a policy and routing layer, not just a traffic proxy.
- You can bind workload class to capacity tier (fractional vs full GPU, reserved vs flex-start, etc.) with explicit rules.
For enterprise architecture, this is the real story: GPU allocation can move from “ticket + tribal knowledge” to declarative platform policy.
Reference pattern: three inference lanes
A practical pattern is to define three lanes behind one gateway:
-
Lane A — Interactive SLO lane (premium): customer-facing copilots, exec workflows, incident copilots. Prioritise latency, stricter admission control, reserved/full GPU where needed.
-
Lane B — Standard enterprise lane: internal assistants and team automation. Prefer fractional GPUs with budget caps and graceful degradation.
-
Lane C — Batch/eval lane: offline generation, evals, synthetic data, red-team jobs. Flex-start and opportunistic capacity first.
All three lanes share common controls:
- policy-based routing,
- per-tenant quotas,
- queue limits and timeout classes,
- fallback model strategy,
- cost and SLO telemetry.
Architectural implications
1) Platform operating model
Move from “infrastructure team provisions GPU” to “platform publishes capacity classes + policies.”
That aligns with modern platform engineering: product-like interfaces, clear SLOs, and enforceable governance.
2) FinOps and chargeback
Fractional allocation improves utilization, but only if paired with tags and policy:
- tenant/workload tagging at ingress,
- showback by lane,
- budget envelope by product domain.
Without this, fractional GPUs can still become ungoverned sprawl.
3) Reliability engineering
A gateway-centric design enables deterministic saturation behavior:
- cap queue depth,
- explicit 429/backpressure,
- downgrade path (smaller model, lower max output, reduced tools).
This avoids the classic retry storm that collapses shared inference clusters.
4) Governance and risk
By routing through a single control plane, you can enforce:
- model allowlists per data classification,
- tool/action policies per tenant,
- mandatory logging and trace IDs for regulated flows.
The net effect: faster delivery and cleaner auditability.
30/60/90-day adoption plan
30 days:
- classify workloads into latency-critical, standard, and batch/eval;
- add gateway request tags (tenant, app, workload class);
- baseline p95 latency and cost per 1k requests by class.
60 days:
- roll out lane-based routing policies;
- move standard workloads to fractional GPU classes;
- implement quota + queue + timeout policy bundles.
90 days:
- enable automated fallback playbooks under saturation;
- publish a self-service capacity class catalog;
- implement monthly architecture review on SLO/cost drift.
The takeaway
The strategic value is not “new VM sizes.”
The strategic value is this: you can treat LLM capacity as a governed control plane primitive—with explicit tradeoffs across latency, cost, and risk.
Teams that formalize this now will scale agentic AI faster than teams that keep running one undifferentiated GPU pool.
Sources
If you want, I can share a one-page policy template for the three-lane inference model (routing rules, quota defaults, and saturation fallback) that your architects and platform team can adopt immediately.
Comment “THREE-LANE” and include your primary cloud + whether your top workload is copilots, RAG, or autonomous agents.