Enterprise Architecture
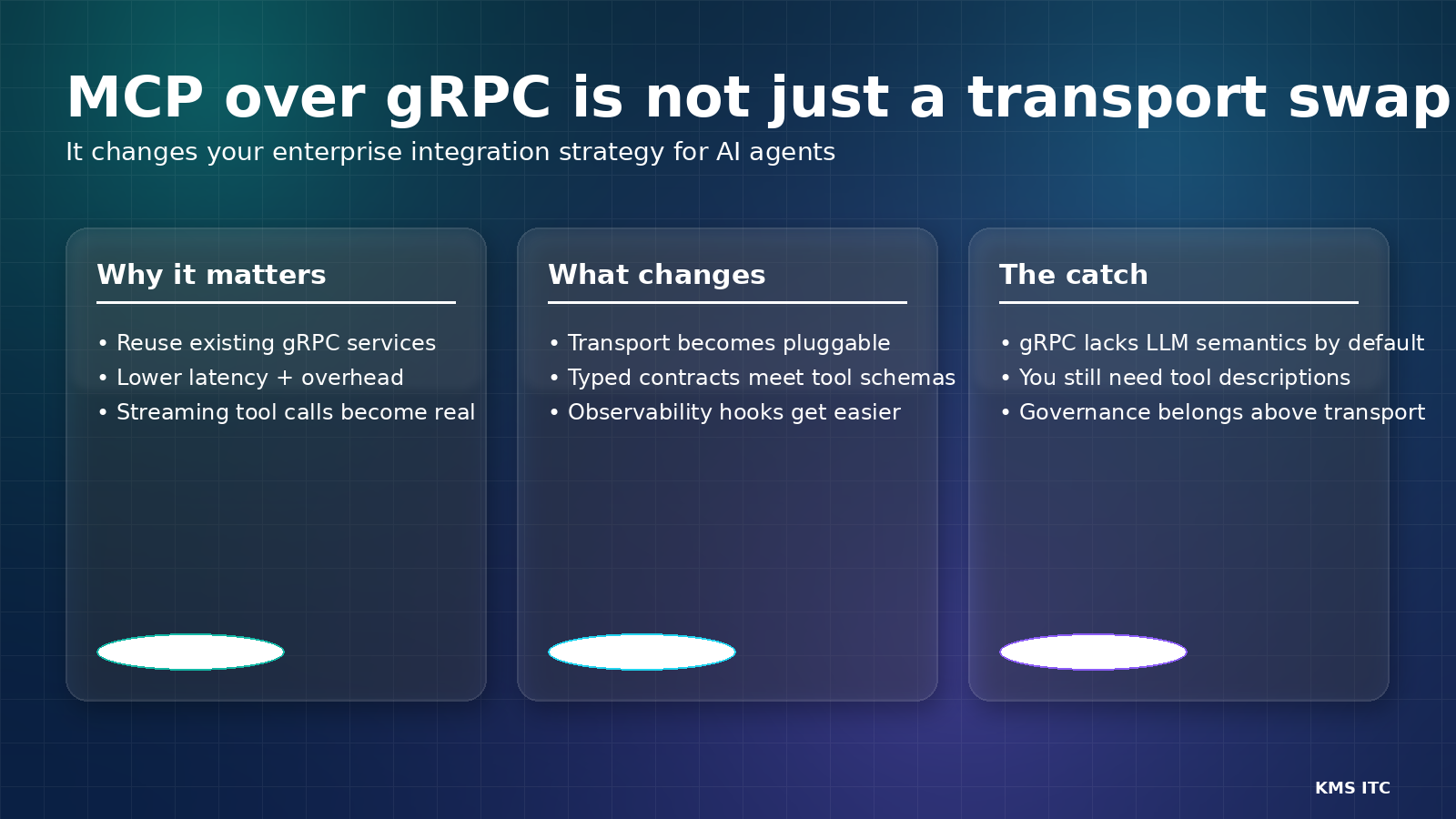
MCP over gRPC isn’t a transport tweak — it’s an enterprise integration decision
Google is contributing a gRPC transport for MCP. The win isn’t just performance — it’s aligning agent tool-calls with your existing service mesh, identity, and observability. The risk: confusing ‘typed APIs’ with ‘LLM-usable tools’.
MCP (Model Context Protocol) is quickly becoming the “tool interface layer” for AI agents: how an agent discovers tools, understands how to call them, and exchanges inputs/outputs with enterprise systems.
Google’s move to contribute a gRPC transport for MCP is a big signal: enterprise agent connectivity is shifting from “demo integrations” to production-grade integration architecture.
1) The real architectural shift: MCP becomes an integration plane
If you treat MCP as “just another protocol”, you’ll likely bolt it on at the edge.
If you treat MCP as an integration plane (like an API gateway + service mesh policies + developer portal for tools), you start asking better questions:
- Who owns tool definitions: app teams, platform team, or an EA-led integration guild?
- Where do policies live: per tool, per agent, or centrally?
- How do we observe and audit tool-use end-to-end?
This is why the gRPC transport matters: it makes MCP fit more naturally into the enterprise defaults many orgs already have.
2) Why gRPC as an MCP transport is attractive (beyond performance)
Yes, gRPC is faster and more efficient than JSON-over-HTTP.
But the bigger enterprise wins are usually operational and governance wins:
A) Align tool traffic with your existing platform guardrails
Many enterprises already standardise on gRPC + service mesh patterns for:
- mTLS everywhere
- consistent authn/z middleware
- request deadlines, retries, circuit-breakers
- OpenTelemetry tracing
- error codes and structured metadata
With MCP over gRPC, “agent → tool” traffic can reuse those patterns rather than creating a parallel, special-case integration stack.
B) Strongly-typed contracts reduce accidental tool misuse
MCP needs to be LLM-friendly, but the tool backend needs to be operator-friendly.
Typed Protobuf contracts can:
- catch malformed inputs earlier
- improve compatibility across languages
- reduce bespoke request/response parsing bugs
C) Streaming is a first-class primitive (important for real tools)
When tools produce partial progress (long queries, batch jobs, retrieval, crawling), bidirectional streaming becomes a practical building block for:
- progress updates
- backpressure
- “agent watches” without brittle long-polling
3) The trap: gRPC reflection is not “tool semantics”
This is the key EA point:
gRPC can describe structure (methods, fields), but LLMs need semantics (intent, constraints, examples, failure modes).
If teams assume “we have .proto, therefore the agent can use the tool safely,” you’ll see:
- tools called with technically valid but business-invalid parameters
- agents discovering methods that are dangerous by default
- poor recoverability because error handling isn’t “agent-shaped”
So treat gRPC as transport/contract — and keep a semantics layer above it.
4) A pragmatic reference model (what to standardise)
If you’re a CTO / platform leader, here’s a clean way to draw the boundary:
| Layer | Audience | What to standardise |
|---|---|---|
| Tool semantics | LLM-facing | Names, descriptions, parameter constraints, examples, safety boundaries |
| Transport + runtime | Platform-facing | JSON-RPC over HTTP for compatibility; gRPC for platform alignment and streaming |
| Policies + controls | Business-facing | Identity mapping, method-level authz, budgets, audit trails, eval regression tests |
Layer 1 — Tool semantics (LLM-facing)
Standardise:
- tool names, descriptions, parameter constraints
- example calls and expected outputs
- safety boundaries (what the tool must never do)
Implementation hint:
- Put this into a tool registry (developer portal-style) with reviews and ownership.
Layer 2 — Transport + runtime (platform-facing)
Allow multiple transports without changing tool semantics:
- JSON-RPC over HTTP for compatibility
- gRPC for platform alignment and performance
Layer 3 — Policies + controls (business-facing)
Centralise:
- identity mapping (user ↔ agent ↔ service accounts)
- method-level authz (least privilege)
- budgets (latency/cost/tool-call caps)
- audit trails (who/what/when/why)
- evaluations (regression tests for tool-use)
5) Decision guide: when gRPC transport is worth it
Move toward MCP over gRPC when most of these are true:
- you already have gRPC standards and internal toolchains
- you run a service mesh with mature identity and policy controls
- you need streaming semantics (progress, watches, long-running tools)
- you want consistent observability across microservices and agent tool calls
Stick with JSON-RPC transport (for now) when:
- your “tools” are primarily SaaS REST APIs and lightweight functions
- you have mixed maturity and want the simplest cross-language onboarding
- the integration complexity is currently organisational, not technical
6) What to do next (a 30-day plan)
If you’re building an enterprise agent platform, don’t start by arguing transport.
Start by building the control plane once, then let transport plug in:
- Define a tool taxonomy + ownership model (who publishes and reviews tools)
- Build a tool registry with:
- descriptions, constraints, examples
- risk labels (read-only vs state-changing)
- Implement policy gates:
- method-level authorisation
- budgets and rate limits
- Require evals for every tool:
- golden tasks
- failure-mode tests (timeouts, perms, partial data)
- Pilot gRPC transport with 1–2 internal gRPC services where streaming and mTLS matter
Sources
- InfoQ — MCP gRPC transport
- Google Cloud — gRPC transport for MCP
- Anthropic — Model Context Protocol
- GitHub — gRPC transport issue
If you’re rolling out AI agents across multiple teams, comment MCP BLUEPRINT and I’ll share a lightweight reference checklist for: tool ownership + policy gates + evaluation in CI.